The unglamorous question every senior AI mandate has to answer.
Most senior teams I talk with have shipped a lot of AI features in the last two years. Most are also quietly worried that the portfolio isn’t adding up to anything coherent. The discomfort is real and the cause is rarely the features themselves.
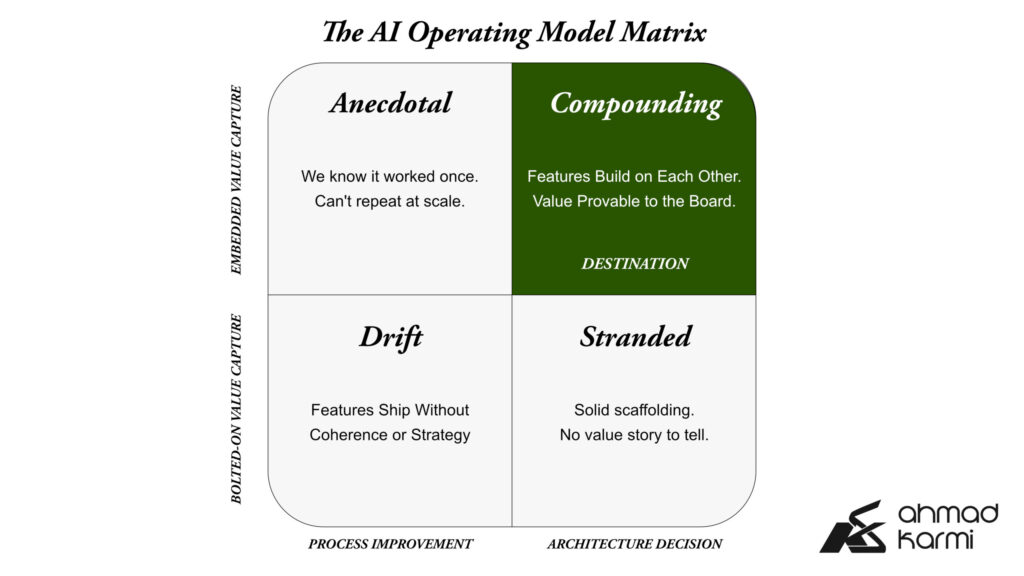
The cause is usually that the operating model underneath the features hasn’t been built. AI features only compound when the layer beneath them is honest about who decides what gets shipped, what gets retired, what standards everyone shares and where the value-capture sits. Without that layer, organizations end up with portfolios that look impressive in slide decks and feel chaotic in practice.
I’ve spent just over a year working on this layer rather than on shipping more AI features. Standards, tooling, deployment patterns, the way design and engineering and product hand work to each other in an AI-augmented context. The unglamorous infrastructure work that no executive asks for in the abstract but every leadership team wishes they had once they’re three or four AI launches in.
This piece is the thinking I’ve come to after a year inside that work. Not a framework you can adopt wholesale, more a set of observations that might save someone else twelve months of figuring out the same things from scratch.
The framework is an architecture decision, not a process improvement
The first mistake I see most teams make is treating the AI delivery framework as a productivity initiative, as if the question is how to ship AI features faster. It isn’t. The question is what infrastructure has to exist so that AI features ship correctly, repeatably, with sustained quality, and in a way that the organization can defend to its board two years later.
That’s an architecture question, not a process improvement question. The two get confused because they sometimes use the same language (workflows, standards, handoffs) but the answers diverge sharply.
A process improvement project asks: how do we move faster through the existing structure? An architecture project asks: what is the structure, and is it the right one?
I’ve come to think the AI delivery framework is the single most underrated architectural decision senior product and engineering leaders will make in this decade. It’s also the one most likely to get delegated downward because it doesn’t look like an executive-altitude problem. That’s a mistake. The framework decisions made in the first year of an AI mandate constrain everything that follows.
The value-capture mechanism has to live inside the framework
The second mistake I see is building the AI delivery side of the framework first and adding value capture later. This sounds reasonable. It almost always fails.
The reason is that value capture isn’t measurement. It’s the part of the framework that defines what success looks like, who’s accountable for it, and how outcomes feed back into prioritization. If that’s bolted on after the delivery work has already started, the prioritization stays driven by whatever forces existed before, which is rarely the value the AI features actually generate.
Practically, this means asking value-capture questions at the same time as architecture questions. What outcome are we measuring? At what level of granularity? Who owns the measurement? What’s the loop from measurement back to prioritization? If those answers aren’t designed into the framework, the framework will produce features that ship cleanly but don’t compound.
This is the retroactive measurement problem, and oh boy is it real. It’s why so many AI portfolios become un-defendable to boards by year two. The data wasn’t properly captured (if at all) because the framework didn’t require it.
Federated organizations break harder than centralized ones
The third lesson is about scale. AI delivery frameworks that work in a single team or single business unit don’t translate to federated organizations. By federated I mean any structure where a central group sets direction and operating units actually deliver: multinational groups with country operating companies, conglomerates with vertical business units, holding structures with portfolio companies.
The hub-and-spoke design that gets drawn on whiteboards looks elegant. It fails at the moment a business unit has to integrate the central framework into their commercial reality. The unit has its own legacy stack, its own customer base, its own commercial rhythm, its own assumptions about what AI is for. The central framework either accommodates these or it doesn’t get adopted.
The path I’ve seen work is to design the framework with handoff in mind from day one. That means giving operating units real authorship over the local instantiation, not just consultation. It means accepting that some of the framework will look different in different parts of the organization, and writing the framework so that variation is allowed without compromising the parts that have to be uniform. It means investing as much in the change-management side of the framework as in the architectural side.
The unsexy version of this work is hard, slow and politically uncomfortable. Most people skip it. That’s why most federated AI programs underperform their strategy decks.
The bilingual problem changes the architecture all the way down
There’s a version of this that’s specific to MENA-headquartered organizations and to anywhere serving meaningfully bilingual audiences. Most AI infrastructure imported from Silicon Valley assumes English-first content with translation as a fallback. That assumption breaks immediately for any market where users are reading and acting in two languages with different scripts, different cultural references and different content velocities.
The honest framework for these markets treats Arabic and English (or whatever the bilingual pair is) as parity inputs, not translation pairs. That changes the architecture all the way down. The data layer has to classify content with parity. The recommendation systems have to understand that user behavior in one language doesn’t substitute for behavior in the other. The personalization surfaces have to render natively in both. The evaluation frameworks have to measure parity at the user-experience level, not at the asset-translation level.
This is harder than it sounds. It requires the data engineering team, the ML team, the product team and the editorial team to share assumptions about what bilingual parity actually means. Most organizations don’t have that shared understanding because nobody’s forced the conversation. The framework forces it.
I’m increasingly convinced this is one of the few defensible competitive moats left in the AI space for regional groups. The big platforms can ship better English-first AI than any regional group can. They cannot ship better Arabic-and-English-at-parity AI, because the infrastructure decisions they made years ago foreclose it. Regional groups that build for parity from the architecture layer up have a window to capture customers the big platforms can’t serve. Almost nobody is building for it intentionally.
Why this matters more in 2026 than in 2024
Two years ago, AI experimentation budgets were generous and accountability was loose. Boards trusted that AI investment would pay off because everyone else was investing. The cost of running AI portfolios was small relative to the strategic optionality they bought.
That’s changed. AI portfolios are expensive now. Boards are asking what the spend bought. The answers organizations are scrambling to give depend almost entirely on whether there was a framework underneath the experimentation. The teams that built one are answering in operating-model terms with measurable outcomes. The teams that didn’t are answering in feature lists, which doesn’t satisfy a board.
The senior AI mandates being scoped right now are mostly about cleaning up this gap. Not just shipping more features. Building the framework retroactively, capturing value-realization where it should have been measured eighteen months ago, and getting the operating model into shape before another budget cycle goes by. That’s the real work the next wave of AI Director and VP roles are being asked to do.
It’s also why the senior people taking these roles need a different set of skills than the AI product roles of two years ago. Less about feature ideation, more about architectural judgment. Less about evangelism, more about operating discipline. Less about velocity, more about sustained compounding.
The question to ask first
For senior people looking at AI mandates in 2026, the question I’d ask first isn’t about the strategy or the features. It’s: what’s the operating model underneath? If you can’t answer in two sentences, the strategy doesn’t matter yet. The framework comes first.
If you can answer it, the next question is whether the framework treats value capture as a first-class concern or an afterthought. Then whether it accommodates federated complexity from day one. Then whether it handles bilingual or multi-market contexts honestly.
These are unglamorous questions. They don’t make good keynote content. They also separate AI organizations that compound from organizations that drift.
The discipline matters more than the features. If your AI mandate is going well in 2026, it’s probably because someone has been doing this unglamorous work in the background. If it isn’t, that’s almost certainly where to look.


